The difference between the elite experimentation teams and everybody else fundamentally comes down to one thing:
Iteration.
The best teams know how to iterate on an experiment result to drive consistent, long-term wins for their programs. The less skilled teams don’t.
None of this will be at all revelatory to most CRO practitioners – the importance of iteration and learning is well understood.
What is much less understood is the process by which elite teams actually execute iteration. This turns out to be a much more intricate problem than most people appreciate.
As the world’s leading dedicated CRO agency, our entire approach to experimentation at Conversion is built around iteration. In fact, emphasis on iteration is a huge part of the reason that elite brands like Meta, Microsoft, KFC, Dominos, Whirlpool, and others have selected us as their CRO agency partner.
In this blog post, we’re going to share the secrets of our approach to iteration, teaching you how we isolate learnings from a/b tests to inform future iteration strategies that drive long-term wins for our programs.
What is iteration and why is it important?
We’ll keep this section short and sweet because we’re assuming that most people will already know what iteration is – but for those that don’t:
Within the context of experimentation, iteration is the process by which you take learnings from one a/b test and apply them to future tests to drive further impact for your program.
Think of it like this:
At its most fundamental level, experimentation isn’t really about optimizing websites; it’s about generating high-quality knowledge.
Every test you run, whether a winner or a loser, generates knowledge about your users – the kinds of things they like, dislike, are motivated by, put off by, etc.
Iteration is the art of extracting this knowledge from your tests and using it to inform future tests.
But here’s the thing: those future tests will also generate learnings themselves, meaning that the opportunities for continual learning – and continual improvement – are potentially endless.
This whole process is best illustrated with a flywheel:
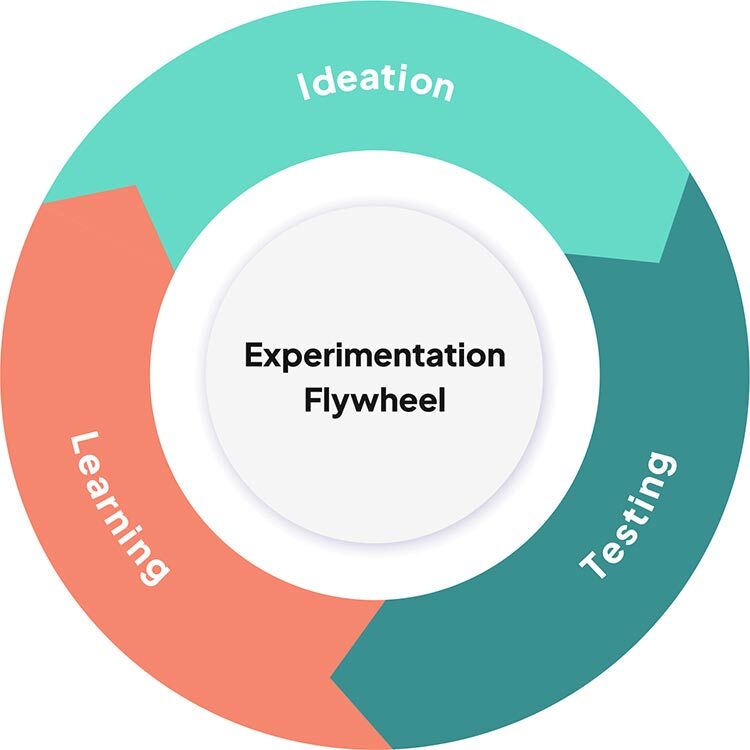
Testing generates learnings; learnings inform ideation; ideation powers testing, etc.
So, in sum: by placing iteration at the heart of your experimentation strategy, you’ll be putting yourself in the best possible position to drive consistent, long-term impact with your program.
How do we isolate and extend learnings from an a/b test?
Now that we’ve covered the importance of iteration, we’re now going to dive into how we as an agency actually do it.
The first part of this process is about isolating learnings from a/b test results.
As an agency, we’ve spent a lot of time thinking about this challenge, and we’ve developed what we think is an optimal solution.
To understand it, consider the following experiment, taken from a program we ran for one of our clients, a global retail brand:
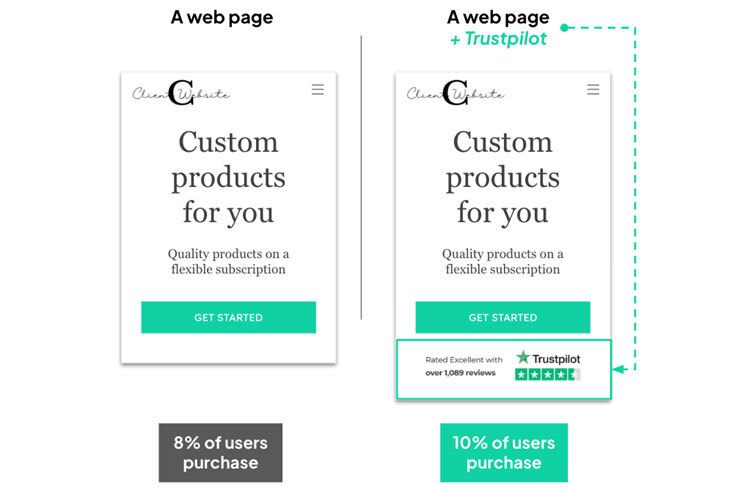
In this test, what have we learnt?
Well, the most explicit learning we can take from this experiment is that ‘adding a Trustpilot logo to the homepage increased the conversion rate by 25%’.
This is good, but it doesn’t give us a whole lot of information about what we should do next, other than that maybe we could try adding a trustpilot logo to other pages on the website.
Instead, we need a way to push this explicit learning further to draw broader inferences from the result. For example:
- Trustpilot reviews are a kind of Social Proof, so we know that showing social proof is likely to be an effective way of increasing the conversion rate
- Social proof works by building Credibility, so we know that helping users believe in the credibility of our site and brand is likely to increase the conversion rate
- And establishing Credibility is a means of engendering Trust in the user towards our website and brand – so we know that enhancing trust is likely to increase our conversion rate
By formulating our learnings at different levels of generality (trustpilot review > social proof > credibility > trust), we’re able to go beyond our initial execution to consider the broader implications of the result – and, importantly, what we might want to test next.
So the next question you may ask is, ‘how do I draw this kind of broader inference from my tests in a consistent way?’
Well, as mentioned above, we’ve spent a lot of time thinking about this particular problem, and we’ve developed a comprehensive framework to help us solve it.
Enter stage left: the Levers™ Framework.
Developed over a 16 year period, the Levers Framework is a comprehensive taxonomy of the user experience features that influence user behaviour.
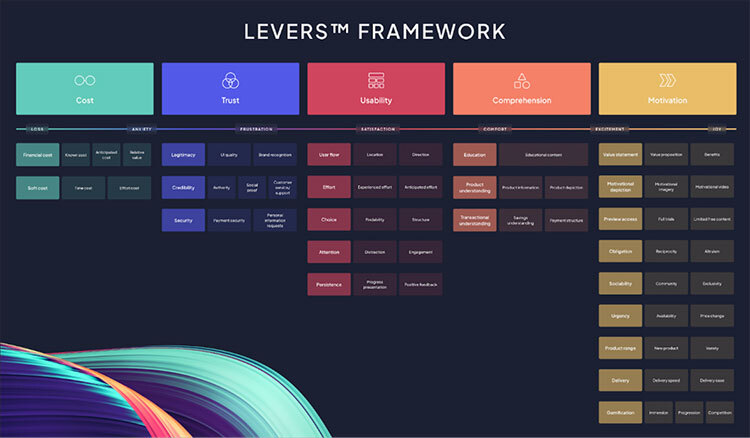
We could talk about the Levers Framework all day – for those that are interested, you can find more information here and here – but the important thing to know now is that the framework allows us to categorize every experiment we run at three levels of generality, relating to a specific Master Lever, Lever, and Sub Lever.
So, to give an example: the Trustpilot experiment mentioned above would fall under the ‘Social Proof’ Sub Lever, the ‘Credibility’ Lever, and the ‘Trust’ Master Lever.
By allowing us to formulate our learnings at three different levels of generality, we’re then able to much more easily consider how we might want to iterate on a result. For example:
- To build further Social proof, we could experiment with adding customer testimonials, awards badges, user generated content, etc.
- To build Credibility, we might want to experiment with some of the other Sub Levers that fall within this category, i.e. Authority or Customer Service/Support. We could do this by, for example, including the badges of reputable institutions to which our client belongs or by including chat functionality on the site.
- To build Trust, we might well experiment on any of the other Levers that fall within the Trust Master Lever. The opportunities for further testing here are almost endless.
As you can see, this framework essentially means that in an instant we’re able to go from a single experiment result to an almost limitless supply of future iteration ideas.
Moreover, by allowing us to draw these broader inferences in a structured way, the framework ensures that there is a consistent, repeatable method to our iteration approach.
How to iterate on different kinds of results
In the previous section of this post, we covered the broad process by which we iterate on winning results to drive further impact for our programs.
Put briefly: when you find an effective lever, our recommendation is that you exploit that lever relentlessly, for as long as it continues to deliver value. Consider all of the different possible test executions you can run on your Sub Lever, Lever, and Master Lever to drive further impact – and then run them.
With one of our clients, for example, we’ve run 46 iterations on a single lever – and it still delivers results to this day!
For losing and inconclusive experiments, on the other hand, there are some additional considerations to factor in.
As a pretty reliable rule of thumb, a test will be inconclusive or lose for one of two reasons:
- Execution – the lever you selected may actually be effective, but the execution you chose may be poor.
- Lever – the overarching levers you’ve tested are themselves ineffective in this context. This reason breaks down into two further subtypes:
a. The specific Sub Lever you’ve chosen to test is ineffective, but the general formulation of your problem re: Master Levers and Levers is correct.
b. The general Master Levers and Levers are ineffective.
To identify the specific cause of the test’s loss – and therefore work out what to do next – here is a general postmortem process we would recommend.
1. Consider ways that the test execution could be improved
The last thing you want to do is reject a potentially fruitful avenue of testing prematurely due to a suboptimal execution.
For example, maybe you’ve added social proof to your landing page, but you’ve placed this content at the bottom of the page where nobody can see it. In this instance, social proof may well be effective as a lever, but the poor execution means the result is negative or inconclusive.
As a consequence of this kind of result – which often isn’t as obvious as the example shown above – we would always recommend that you explore different ways of executing on your chosen Sub Lever to ensure that the initial execution isn’t at fault for the losing result.
For example:
- Was there some aspect of your initial execution that was particularly weak?
- Did the data from your test flag an obvious improvement you might be able to make to the execution, e.g. maybe users aren’t interacting with an element you’ve introduced to the page because they haven’t seen it rather than because they’re not interested.
- Were there potentially confounding variables in your initial test that may have contaminated the purity of your result?
Once you’ve ideated a second, hopefully improved execution for your Sub Lever, we would recommend that you run this execution as a separate experiment.
As a more general point, any one experiment execution will almost always underdetermine the kinds of broader learnings we want to develop in our experiment programs. As such, we would typically recommend running multiple executions on any given lever before deciding to fold that lever completely.
2. Consider different Sub Levers
If you run multiple executions on the same Sub Lever and it continues to lose, then odds are that your Sub Lever is ineffective in your site context and ought to be folded.
But this doesn’t mean that you should give up entirely on your Master Lever and Lever. On the contrary, your Master Lever and Lever may be sound – but your Sub Lever may be where the issue is.
Consider the following example, taken from a series of tests we ran with a global Saas company:
User research indicated that there was a lack of trust in the efficacy of our client’s service, so we decided to pull the ‘Authority’ Sub Lever to build credibility and improve trust.
The client had a big hobbyist base accounting for the majority of its revenue, but its product was also used by many leading institutions within its space. The question became ‘can we leverage the company’s connections to these leading institutions to enhance its appearance as an authority?’
To test this, we added a new entry to the website’s benefits bar to emphasize the number of institutions that were using this particular product (see image below).
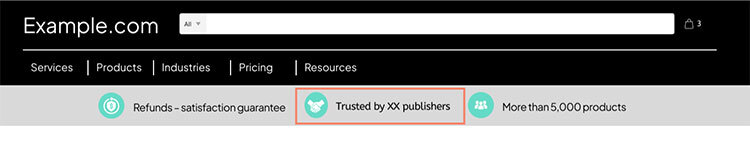
Unfortunately, this test – and a number of others on this Sub Lever – was a loser.
Based on some fairly extensive UX research, we had good evidence that there was a credibility issue on the website, but clearly the Authority Sub Lever was not effective at solving it.
Rather than folding this general Lever, we therefore opted to pivot to another Sub Lever that falls under the Credibility Lever – in this instance, Social Proof.
As such, we developed a new Social Proof test concept, which involved a very similar execution to the Authority test but with a changed emphasis from the number of publishers to the number of product users (see image below).
This test turned out to be a strong winner.
Clearly, then, we were correct in diagnosing a Trust issue on the website, but we had initially tried to solve this issue with the wrong Sub Lever (Authority). By pivoting to an adjacent Sub Lever, we found a more effective solution to the problem.
From here we were then able to ask: how and where else might we be able to build Trust and Credibility via Social Proof on the website?
3. Finally, fold
If you’ve tried multiple executions on your Sub Lever and have subsequently pivoted to adjacent Sub Levers to no avail, then it’s now time to fold this Lever and move on.
The good news is that you’ve now got fairly conclusive evidence that this specific Lever is a dead end. All value has been taken off the table, and you can move on.
And the even better news is that while you’ve been exploring this Lever, you will hopefully have been running other tests on other Levers that have opened up fruitful new avenues of testing that you can now focus your energy on.
Worth noting: it's important to remember that losing experiments can tell you more than inconclusive experiments. While no non-winning experiment is sufficient to rule out a lever's importance (even a loser), losing experiments have the advantage of telling you something more. What you are doing at least matters to users. So a better message or change relevant to that lever might well intervene in a way which makes a positive rather than negative difference. Equally, simply doing less of, or the opposite, of what had the negative effect might be most effective.
Final thoughts: should you trust the Levers™ Framework?
Any experimentation team can deliver the odd, one-off win, but if you’re looking to achieve long-term results, continual learning and iteration need to be at the heart of your strategy.
The Levers Framework is a ready built tool that we ourselves use to support our iteration strategies, and we would highly recommend that you take advantage of it too.
One question you may still have, however, is ‘Why should I trust the framework? How can I know that it captures something real?’
Aside from the fact that we ourselves have been using the framework to supercharge our iteration strategies for years, we actually do have some good data on its validity:
ConfidenceAI, our machine learning assisted prioritization tool, is able to predict the results of a/b tests with around 63% accuracy – significantly higher than the average CRO practitioner based on standard industry win-rates.
Almost all of ConfidenceAI’s predictive power comes from two central taxonomies that we tag each of our tests with.
The first taxonomy, unsurprisingly, is ‘Industry’: which industry is this test being conducted in?
And the second taxonomy – you guessed it – is the Levers Framework.



