An argument for why the web should pool its resources, and share the same CDN.
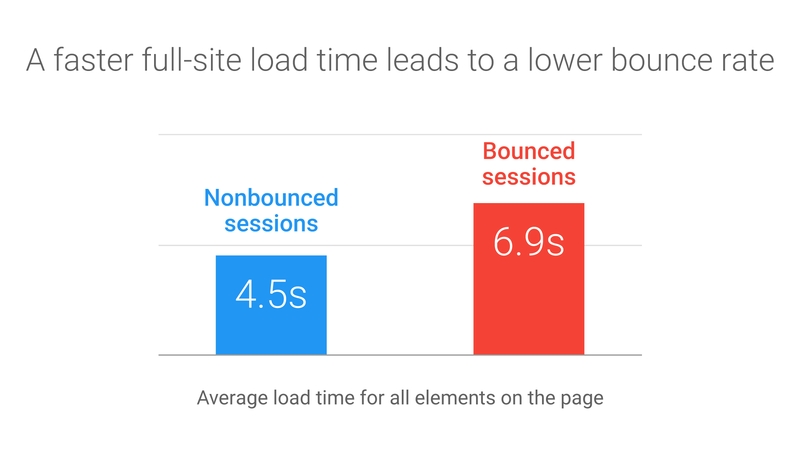
Site speed is rapidly becoming understood as one of the most important factors to success online. And not just because Google penalises slow websites (although that is what seems to drive most companies), but because it genuinely makes a difference to onsite experience. Despite 5g and gigabit broadband, we want our experiences to happen quickly, and this means all resources should download immediately.
So, how do we do this? Compress our websites, write clean code, stop using unnecessary libraries, optimise our images, and.. that’s about it right? No.
Infrastructure is a huge factor in how quickly things load. To date, we’ve understood that CDNs help with this – placing the content physically closer to the user means there’s less distance to travel, and so things download faster. Combined with efficient caching policies, usually only changed when something complains, and we think that’s sort-of handled.
But all of your files are still typically located on your infrastructure – not kept in one giant, global pool of files. When it’s your code, and nobody else has a need for it, that’s fine. But what about your libraries, SaaS tools, etc.?
jQuery, still the worlds most popular library, powers 90% of the top 100k websites globally, and 83% of the top 1m.
Facebook SDKs, Modernizr, SlickJS, UnderscoreJS etc. are also hugely popular, with 10-26% of the worlds top million websites using them.
So – how many websites does an average user visit? And how many of these websites use the same libraries? My guess – loads.
If we all shared our resources
If all files were located in a single place, every website you visit could have a whole bunch of requests which are already downloaded. 0-2 millisecond “download” time, every time. This means:
The fundamental building blocks of your website – frameworks like Angular, React etc., assembly libraries like Webpack, jQuery, any shivs or feature detection like Modernizr, html5shiv, etc.
Animation or feature libraries – jQuery UI, Slick Slider, etc.
SaaS tools – analytics, insights/session recording, experimentation, retargeting, etc.
Shared images – social media icons, etc.
Stock photography.
You get the idea – there’s a lot to be shared.
90% or more or each of these things never change. Webtrends Optimize, for example, has the code which is “our product” and the configurations which are unique to each customer. I’m certain that if you compared Google Analytics libraries across multiple accounts, that’d be almost identical too. If we tried (not even that hard), we could easily separate out the two files.
In fact, I’ve seen multiple SaaS tools load the same libraries, within their own code.
Thinking about users, not page loads
Sometimes it’s not easy to remember that we’re not the centre of the universe. Users are on multiple websites, doing a range of different things.
If we normalised the idea of shared libraries, browsers may well be inclined to build up a small cache of libraries too. A few megabytes of cached files is nothing, in comparison to precious seconds saved in load times and the perception that they’re able to load pages faster than their rivals. This can only happen if enough websites say “we want to use a specific version of this file” – the more the better.
Interested in taking part?
All it takes is a simple file store and a CDN that we all use, contribute to, and share. Some great ones already exist, and it wouldn’t take much to make a new one.
Let me know if you’re interested, and if enough people are we can mobilise!


